10 minutes
Autoencoder e Anomaly Detection per la previsione del fallimento aziendale
Step 1: Suddivisione del dataset
La suddivisione del dataset è stata effettuata utilizzando la funzione train_test_split del modulo sklearn.model_selection, dopo aver caricato i dati con la libreria pandas. Il primo passo fondamentale è stato separare i record delle aziende classificate come “sane” (valore 0 nella colonna class) da quelle in fallimento (valore 1).
Il motivo risiede nella natura stessa dell’anomaly detection tramite autoencoder: il modello deve essere addestrato esclusivamente su dati normali (le aziende sane) per imparare a ricostruire accuratamente la “normalità”. In questo modo, in fase di test, il modello restituirà un errore di ricostruzione sensibilmente più alto quando incontrerà esempi di aziende prossime alla bancarotta, che verranno quindi identificate come anomalie.
Il dataset delle aziende sane è stato suddiviso destinando il 70% al train set e il restante 30% ripartito equamente tra validation set e test set. Poiché questi ultimi due devono contenere entrambe le categorie di aziende per una valutazione corretta, sono stati successivamente integrati con i dati delle aziende fallite e rimescolati. Per la valutazione finale, è stata preservata la colonna dei target per ogni set.
Step 2: Pulizia dei dati
Per lavorare sul dataset Polish Companies Bankruptcy è stato necessario rimuovere i valori nulli dalle feature e procedere con una normalizzazione, fondamentale data la presenza di valori molto distanti dalla media.
Per la gestione dei valori mancanti è stato utilizzato SimpleImputer, che di default sostituisce i dati nulli con il valore medio della colonna. Questa strategia è efficace per colonne numeriche; in caso di variabili categoriche, si potrebbero adottare strategie diverse come il most frequent o il constant.
Per la normalizzazione è stato adottato lo StandardScaler, che esegue la trasformazione utilizzando lo standard score:
$$z= \frac{x-\mu}{\sigma}$$Dove $\mu$ è il valore medio della colonna e $\sigma$ la deviazione standard (che indica quanto i dati siano dispersi rispetto alla media).
In pratica, per ogni colonna viene calcolato lo z-score per ogni singolo valore. Il risultato è che ogni feature viene centrata intorno allo zero, ma non limitata in un intervallo predefinito (a differenza di quanto accadrebbe con un MinMaxScaler).
È fondamentale che i parametri di SimpleImputer e StandardScaler siano calcolati esclusivamente sul set di train (fitting). La trasformazione viene poi applicata a tutti i set, ma utilizzando i parametri derivati dal training per evitare fenomeni di data leakage.
Step 3: Definizione del modello
(Inserire qui i dettagli sull’architettura del modello)
Step 4: Addestramento
Data la dimensione del dataset, è stata utilizzata una strategia di data loading per suddividere gli esempi in batch, ottimizzando l’uso della memoria. Durante l’addestramento (esteso per 100 epoche), i batch vengono elaborati dal modello: le feature vengono compresse nello spazio latente, decodificate per la ricostruzione e infine confrontate con i valori di ingresso per calcolare la loss.
Come ottimizzatore è stato scelto AdamW, mentre come funzione di costo il Mean Squared Error (MSE). Il calcolo della perdita avvia poi la backpropagation per l’aggiornamento dei pesi.
Per monitorare il processo, viene calcolato il valore medio della perdita per ogni epoca. Nello specifico, features.size(0) restituisce il numero di campioni $N_i$ nel batch corrente.
for features, labels in train_loader:
features = features.to(device)
optimizer.zero_grad()
reconstructed = autoencoder(features)
loss = criterion_train(reconstructed, features)
loss.backward()
optimizer.step()
running_train_loss += loss.item() * features.size(0)
epoch_train_loss = running_train_loss / len(train_loader.dataset)
training_losses.append(epoch_train_loss)
La variabile running_train_loss accumula l’errore totale dell’epoca. Poiché loss.item() restituisce la perdita media del batch ($\bar{\mathcal{L}}_i$), moltiplichiamo questo valore per la dimensione del batch ($N_i$) per ottenere la somma degli errori del batch:
L’errore cumulativo totale ($L_{total}$) è la somma degli errori di tutti i $B$ batch:
$$L_{total} = \sum_{i=1}^B \left( \bar{\mathcal{L}}_i \cdot N_i \right)$$Al termine dell’epoca, la perdita media finale ($L_{epoch}$) si ottiene dividendo l’errore totale per il numero complessivo di campioni ($N_{total}$):
$$L_{epoch} = \frac{L_{total}}{N_{total}}$$Questa logica può essere sintetizzata nella formula:
$$\text{running\_test\_loss} = \sum_{i=1}^B \left(\sum_{j=1}^{N_{i}} loss_{i,j}\right)$$Nel ciclo di validazione, eseguito dopo ogni epoca, viene valutata la capacità del modello di ricostruire report sia di aziende sane che fallite. Terminata questa fase, è necessario determinare una threshold (soglia) per identificare le anomalie.
L’idea è calcolare gli anomaly scores sul set di validazione e analizzarne la distribuzione. Qui l’anomaly score è definito come la loss media per ciascun record. Per ottenerlo, è stato usato un criterio di valutazione con reduction='none'(spiegare cosa accade se lascio il default), ottenendo una matrice con l’errore associato a ogni feature per ogni elemento del batch. Calcolando la media lungo le righe, si ricava il vettore degli anomaly scores individuali.
Step 5: Classificazione
Il modello ricostruisce con precisione le aziende sane (errore basso), ma non quelle in fallimento. Se l’errore di ricostruzione supera una certa soglia, l’azienda viene classificata a rischio bancarotta. Il problema centrale è individuare la soglia ottimale. Le strategie testate sono tre:
- Percentile
- Precision Recall Curve
- Modello matematico
1. Precision Recall Curve
Precision e Recall sono metriche fondamentali per valutare i modelli di classificazione:
Precision: indica l’attendibilità del modello quando predice un’anomalia. Risponde alla domanda: “Quando il modello segnala un’anomalia, quanto spesso ha ragione?”
$$P = \frac{TP}{TP+FP}$$Recall: misura la capacità di individuare i casi positivi reali. Risponde alla domanda: “Quante delle aziende realmente in crisi sono state individuate?”
$$R = \frac{TP}{TP+FN}$$
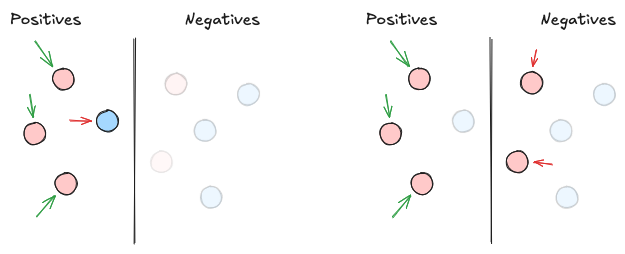
Nell’esempio sopra, vogliamo distinguere palline rosse da blu. Se il modello identifica 4 palline come rosse, ma solo 3 lo sono effettivamente su 5 totali:
- $P = 3/4 = 75%$
- $R = 3/5 = 60%$
È possibile variare la soglia che divide i positivi dai negativi per bilanciare precision e recall. Questo compito è affidato alla funzione precision_recall_curve() di sklearn. Confrontando gli score calcolati (le loss) con i valori di classe reali, cerchiamo l’errore di ricostruzione ideale per definire il fallimento.
Per esemplificare, analizziamo 4 record:
| Target ($y$) | Loss ($y^*$) |
|---|---|
| 0 | 0.0388 |
| 0 | 0.1552 |
| 0 | 0.2076 |
| 1 | 0.1097 |
Scegliendo come soglia il primo valore di loss ($0.0388$), tutti i record con loss $\ge 0.0388$ vengono classificati come anomalie ($\hat{y}=1$):
| Target ($y$) | Loss ($y^*$) | Classificazione ($\hat{y}$) |
|---|---|---|
| 0 | 0.0388 | 1 |
| 0 | 0.1552 | 1 |
| 0 | 0.2076 | 1 |
| 1 | 0.1097 | 1 |
Nota di progetto, il modello fa schifo a classificare perché è strano che ci siano questi valori
Calcolando le metriche: $P = 1/4 = 25%$ e $R = 1/1 = 100%$. Iterando questo processo per ogni valore di loss, otteniamo la curva Precision-Recall.
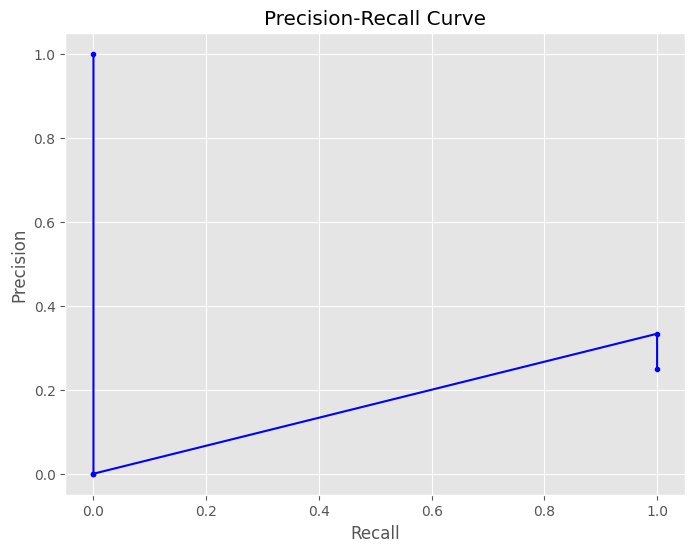
Per trovare la soglia perfetta introduciamo l’F1-score, la media armonica tra precision e recall:
$$F1=2\frac{P\cdot R}{P+R}$$La media armonica penalizza i valori estremi: l’F1-score sarà alto solo se sia precision che recall sono soddisfacenti. Individuato il valore massimo di F1-score nella curva, utilizziamo l’indice corrispondente per determinare la nostra threshold definitiva.
optimal_idx = np.argmax(f1_scores)
optimal_threshold = thresholds[optimal_idx]
2. Percentile
Un’altra strategia adottata, di natura non supervisionata, è quella del percentile. Analizzando la distribuzione degli errori di ricostruzione tramite un istogramma, è possibile definire una soglia per “tagliare” la coda della distribuzione, ovvero la porzione di risultati che più si allontana dalla media verso i valori alti; è proprio lì che, molto probabilmente, si nascondono le anomalie.
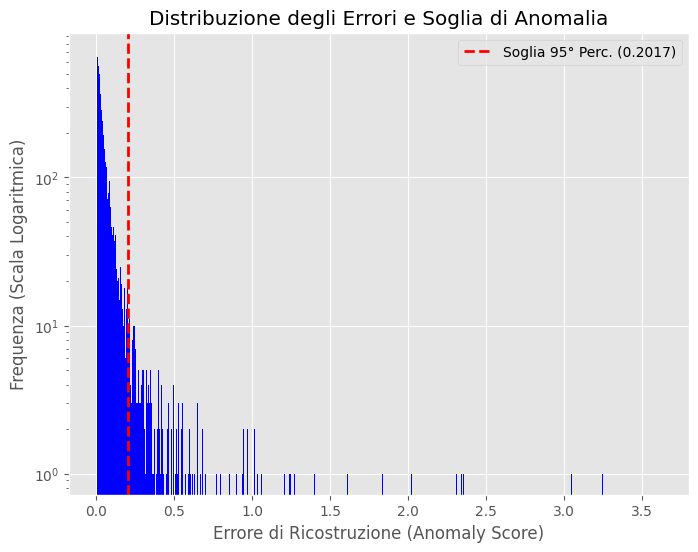 Un’idea per individuare la soglia ideale consiste nel valutare i valori di precision, recall e F1-score iterativamente, testando diversi percentili (ad esempio dall'80% al 99%) per trovare quello ottimale.
Un’idea per individuare la soglia ideale consiste nel valutare i valori di precision, recall e F1-score iterativamente, testando diversi percentili (ad esempio dall'80% al 99%) per trovare quello ottimale.
Valutazione
Valutate le soglie seguendo le due diverse strategie è stato eseguito un report di confronto per valutare i risultati ottenuti. Lo step finale è stato quindi quello di valutare le soglie sul test set
autoencoder.eval()
test_anomaly_scores = []
test_true_labels = []
with torch.no_grad():
for features, labels in test_loader:
features = features.to(device)
reconstructed = autoencoder(features)
loss_matrix = criterion_eval(reconstructed, features)
transaction_scores = loss_matrix.mean(dim=1)
test_anomaly_scores.append(transaction_scores)
test_true_labels.append(labels)
test_anomaly_scores = torch.cat(test_anomaly_scores).cpu().numpy()
test_true_labels = torch.cat(test_true_labels).cpu().numpy()
predictions_perecentile = (test_anomaly_scores > threshold).astype(int)
predictions_argmax = (test_anomaly_scores > optimal_threshold).astype(int)
Nello specifico, utilizzando il calcolo della soglia con il percentile i risultati sono:
precision recall f1-score support
0 0.87 0.97 0.92 6198
1 0.42 0.15 0.22 1046
accuracy 0.85 7244
macro avg 0.65 0.56 0.57 7244
weighted avg 0.81 0.85 0.82 7244
I risultati ottenuti invece sembrano più promettenti utilizzando la strategia dell’F1-Score
precision recall f1-score support
0 0.92 0.86 0.89 6198
1 0.41 0.55 0.47 1046
accuracy 0.82 7244
macro avg 0.66 0.71 0.68 7244
weighted avg 0.85 0.82 0.83 7244
3. Modello matematico
Analizzando il lavoro con il mio relatore, è emersa l’opportunità di calcolare la soglia (threshold) adottando un approccio realmente semi-supervisionato. L’idea consiste nel variare il set su cui viene calcolata la soglia, utilizzando esclusivamente aziende “sane” ed escludendo gli errori di ricostruzione più elevati all’interno di questo gruppo.
Tuttavia, non potendo impiegare il training set, poiché il modello risulterebbe già ottimizzato nella ricostruzione di dati noti, ho modificato il criterio di suddivisione del dataset, creando un ulteriore set di sole aziende sane dedicato esclusivamente alla rilevazione della soglia. Questo approccio presenta sia vantaggi che svantaggi. Il vantaggio principale risiede nella coerenza statistica: la soglia riflette con precisione la distribuzione dell’errore appresa dal modello durante la fase di tuning. Tuttavia, ciò implica che il modello sia estremamente ottimizzato per minimizzare l’errore proprio sui dati di addestramento. Di conseguenza, l’errore di ricostruzione risulterà fisiologicamente più basso rispetto a quello di qualsiasi nuovo dato (anche se sano), con il rischio di generare numerosi falsi positivi in fase di produzione.
Una volta ottenuta la distribuzione dell’errore, su suggerimento del docente, ho provato a modellare i dati tramite una distribuzione gaussiana, definendo la soglia come: valore medio + 2 deviazioni standard. Questo approccio diretto ha però evidenziato un limite: data la natura asimmetrica e fortemente skewed della distribuzione, il modello gaussiano non riesce a rappresentarne correttamente l’andamento, rischiando di produrre una soglia non coerente con la statistica degli errori rilevati. Si è passati quindi a modellare la distribuzione utilizzando una log-normale.
Distribuzione log-normale
Una variabile aleatoria $Y$ segue una distribuzione log-normale se il suo logaritmo naturale $X = \ln(Y)$ segue una distribuzione normale: $Y = e^X$, dove $X \sim N(\mu, \sigma^2)$. Il dominio si restringe, quindi, ai valori strettamente positivi $(0, +\infty)$.
Questa scelta risolve diverse criticità:
- Gestione del dominio positivo: come si nota dall’immagine, i dati partono da zero con una crescita immediata. La gaussiana, nel tentativo di adattarsi ai dati, “sconfina” nell’area negativa (a sinistra dello zero), dove però non sono presenti osservazioni. Tale “dispersione” di probabilità nell’area negativa sottrae altezza alla campana nel quadrante positivo. La log-normale, essendo definita solo per $x > 0$, concentra tutta la sua massa dove effettivamente risiede l’informazione.
- Adattamento della coda: la distribuzione presenta una “coda” che si estende fino a 2.0.
- Nella Normale: la deviazione standard $\sigma$ viene calcolata pesando la distanza dei punti dalla media. Gli eventuali outlier presenti nella coda tendono a incrementare il valore di $\sigma$, allargando la campana. Poiché l’area totale sottesa alla curva deve essere pari a 1, una campana più larga risulta necessariamente più bassa.
- Nella Log-normale: esiste un parametro specifico di forma (shape) che gestisce l’estensione della coda senza influenzare drasticamente la posizione o l’altezza del picco principale.
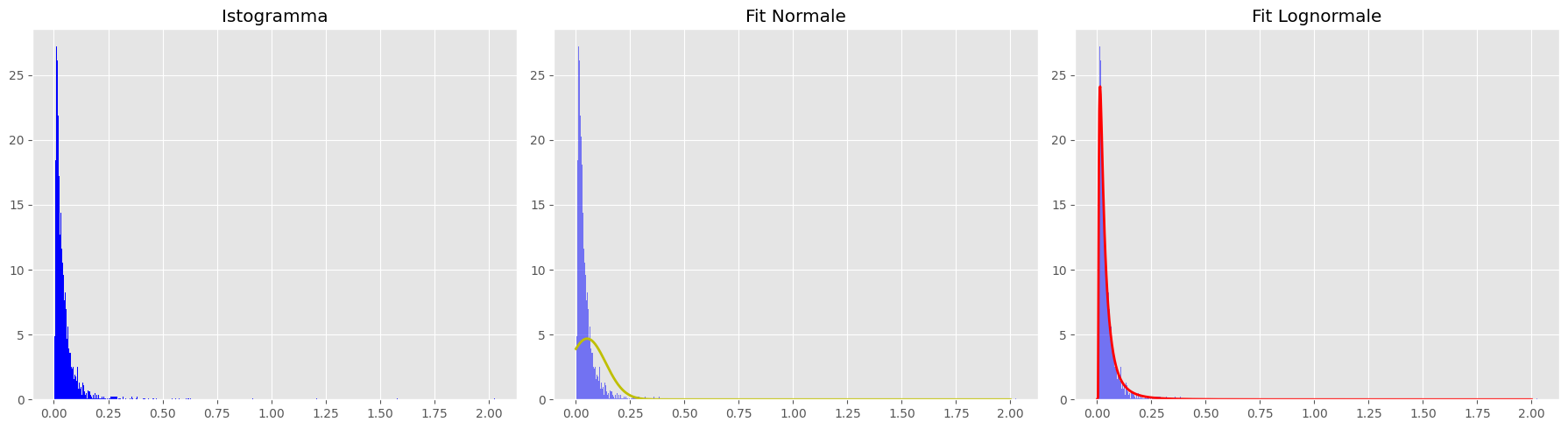
Ma perché preferire un modello matematico a un semplice percentile calcolato sui dati grezzi? Un approccio parametrico permette di astrarre il principio probabilistico della distribuzione, riducendo la dipendenza dai singoli valori e rendendo il risultato meno sensibile a eventuali dati anomali (noise).
Di conseguenza, anche la modalità di calcolo della soglia cambia: invece di calcolare il percentile sul dataset, lo si ricava dal modello tramite la funzione Percent Point Function (PPF), che determina il punto in cui cadrebbe quel percentile se i dati seguissero fedelmente la distribuzione teorica.
Note
- F1 Score: Fondamentale per bilanciare il modello, specialmente con classi sbilanciate.
- Scelta della metrica: In alcuni contesti potremmo preferire una Recall più alta (per non perdere nessuna azienda in crisi) anche a costo di una Precision inferiore.
- Efficienza: Sebbene spiegati passo-passo, i calcoli avvengono tramite operazioni vettoriali tra matrici, sfruttando l’efficienza computazionale dei tensori.
1931 Words
2026-03-31 21:30